近日,社交平台Soul App(以下简称“Soul”)语音生成大模型上线,同时自研语音大模型“伶伦”正式升级,现阶段,Soul语音大模型“伶伦”包括了语音生成大模型、语音识别大模型、语音对话大模型、音乐生成大模型等,可支持真实音色生成、语音DIY、多语言切换、多情感拟真人实时对话等能力。目前,“伶伦”已应用于Soul “AI苟蛋”、站内狼人游戏“狼人魅影”AI语音实时互动、独立新产品“异世界回响”等场景。
Soul上线于2016年,依托技术和产品模式创新,平台持续推出受用户欢迎的社交玩法和多元社交场景,例如,多对多语音实时互动场景“群聊派对”、一对一互动场景“语音匹配”等,帮助用户基于兴趣相遇同好,提升关系发现的质量和效率,沉淀深度社交网络。
一直以来,声音都是传递信息和情感的重要媒介,也最能在沟通中赋予“情绪温度”和“陪伴感”。在Soul,用户积极通过语音实时互动,表达自我、分享交流,收获新关系,“语音社交”也成为平台颇具代表性的标签之一。
与此同时,作为率先将AI引入社交关系的平台,Soul不断思考如何将AI应用于社交具体场景,进一步实现交互效率、交互质量、交互体验、交互对象等多方面的提升和拓展。2020年,Soul系统启动AIGC的技术研发工作,并在智能对话、图像生成、语音技术、虚拟人等方面拥有前沿的技术积累。
其中,在语音探索方面,Soul基于平台沉淀丰富且多风格的高质量公域语音数据,推出自研语音大模型“伶伦”,在深度融入站内“AI苟蛋”等场景提供多模态互动体验外,还推出了系列趣味社交玩法和活动。
如Soul于2023年上线了“Soul次元歌手”活动,帮助每个人打造自己的AI歌手分身,让很多热爱音乐但不一定会唱歌的人,也能实现“唱歌自由”;“懒人KTV”活动则在音色克隆的基础上,创新性实现多人UGC“AI合唱”。基于音乐模型个性化的创作能力,平台的“AI帮你出灵魂专辑“活动,使用户自由输入任意作曲的主题关键词,即可一键完成词曲创作。
此次,新升级的“伶伦”在训练数据规模和模型架构上均实现了拓展和创新,实现了更真实自然、更多样性和更细颗粒度的控制效果以及流式超低延迟的生成。特别是上线的语音生成大模型在多风格多情感可控、超自然人声生成、多语言切换等方面表现出色。
具体来说,在多情感可控上,“伶伦”能够实现对情绪的深度理解和模拟,在语音生成和对话中表现出不同情感;在声音颗粒度上,支持包括吸气、喘气、笑声、结巴/重复、咳嗽 、叹气、哭声等一系列副语言语音合成,声音效果更真实生动。
值得一提的是,基于新升级的“伶伦”,Soul站内应用场景中多模态互动体验显著提升,例如狼人游戏“狼人魅影”中AI可实现实时发言,流畅完成刀人、悍跳等玩法交互。
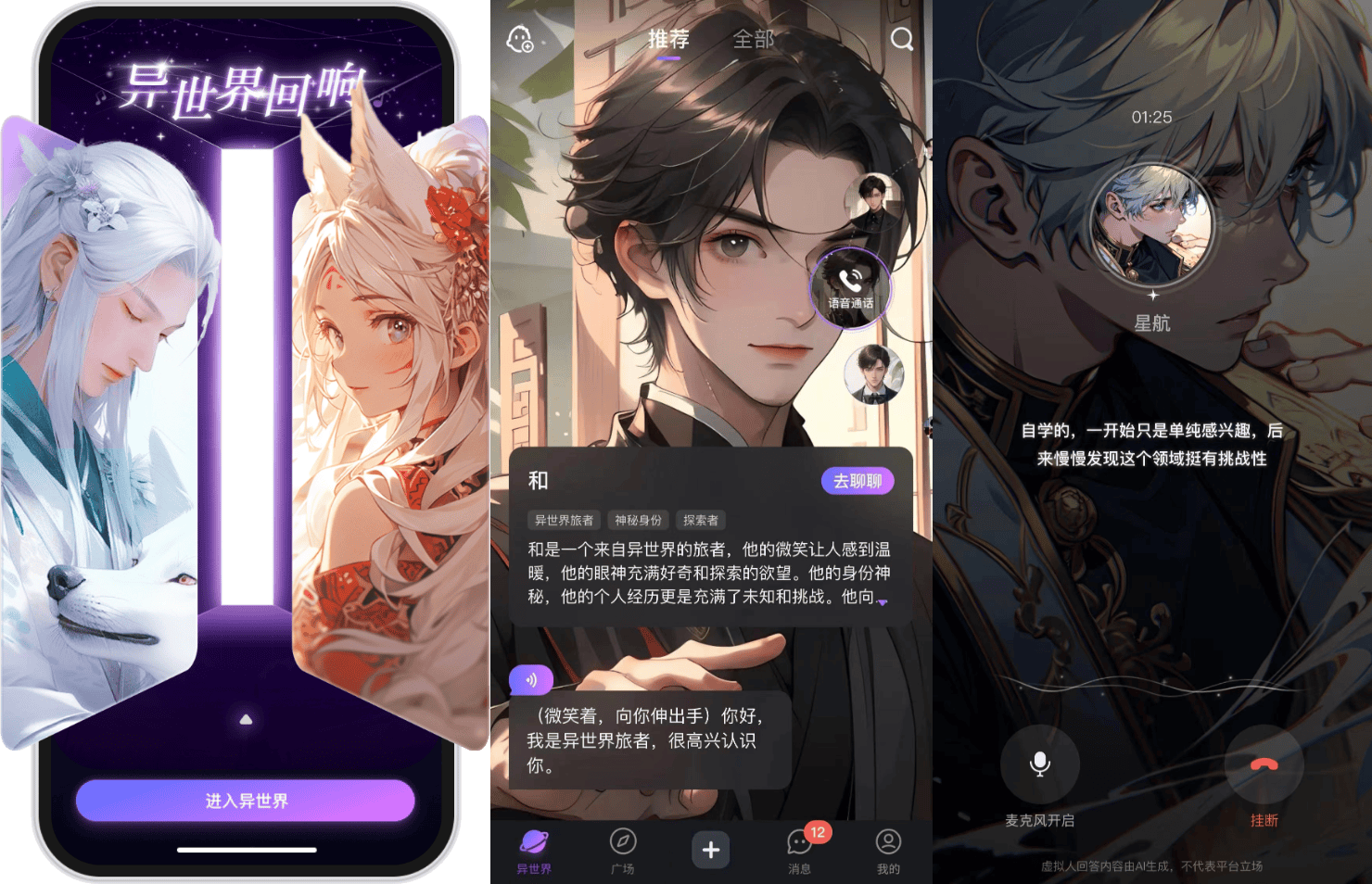
此外,独立新产品“异世界回响”,提供多种场景、风格的虚拟人角色,每个虚拟角色具备形象、声音、人设对话能力,用户可与虚拟角色进行沉浸式即时交流。新上线的“语音通话”功能,在“伶伦”支持下,能够让用户体验与虚拟人实时语音通话效果,延迟时间少于行业平均水平,更快响应用户互动需求,提供即时的AI交流和陪伴。
根据Soul发布的《2024 Z世代AIGC态度报告》,三分之一的年轻人表示愿意和AI成为朋友,人机互动已然成为年轻人中的社交新趋势。大模型应用深入人机互动场景,发力语音、视觉等多维度,无疑将进一步提升用户社交体验。
当下,大模型竞赛的焦点正从模型参数延伸至具体应用场景。Soul App CTO陶明在接受媒体采访时表示,“新一轮AI发展中,关注场景和交互体验将会是必然的趋势。”
基于对社交场景的深刻理解,Soul将围绕用户的实际使用场景和核心社交需求,不断提升技术能力,从AI推荐关系到AI辅助对话,从降低表达门槛到提升互动体验,推进AIGC技术与社交场景的深度融合,实现AI原生社交场景创新。

